3 Strategies to Overcome OpenAI Token Limits
Learn how to use the OpenAI API to have a conversation with GPT-4 and how to exceed the token limits

Published on
May 13, 2024
Read time
22 min read
Introduction
Right now, it’s possible to harness the power of LLMs (large language models) through several public APIs — giving us access to the likes of ChatGPT, Claude and Gemini for use in our own applications.
At a small scale, using these APIs is straightforward. But if we want to support longer conversations or larger amounts of context, sooner or later we will bump into token limits and we’ll need to implement our own workarounds.
In this article, I’ll walk you through three strategies for overcoming these token limits, so that you can support much longer conversations or much more context — or both!
We’ll be using OpenAI’s API in Node.js, but the strategies we’ll learn can be adapted to pretty-much every mainstream LLM in any server-side programming language.
Whether you’re writing a chatbot or using AI tools for something else, under-the-hood most LLMs use a conversational format. Understanding how to make the most of this format is key to making more capable and efficient applications. So, how can we approach the problem of scaling our conversations?
The idea of ‘long-term memory’
This article is not focused on training or fine-tuning models. While fine-tuning can be a fantastic strategy for handling a very large volume of text, it’s also slow: depending on the amount of training data, it can take several hours to fine-tune a model. In many contexts, this is simply too slow.
Instead, we’ll focus on techniques that will significantly increase the length of conversations, but your users will only be waiting for somewhere between a few minutes and a few seconds.
These approaches are sometimes referred to as a “memory system” or “long-term memory”; typically, they involve altering the way a conversation is stored.
The 3 Strategies
In this article, we’ll focus on three approaches to dealing with the issue of scale:
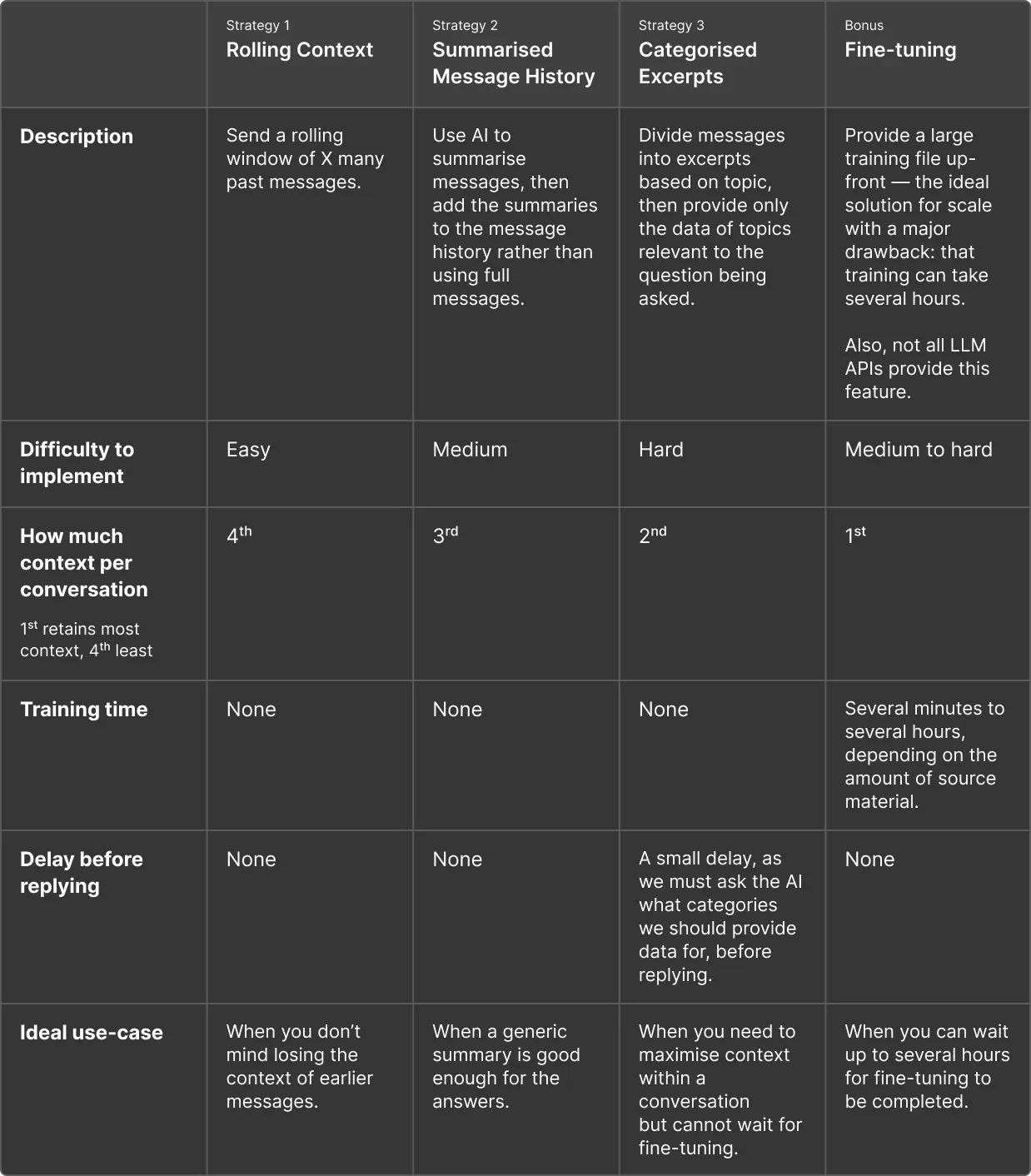
- Strategy 1: Rolling Context. Send a rolling window of X many past messages, and discard earlier messages.
- Strategy 2: Summarised Message History. Use AI to summarise messages, then add the summaries to the message history rather than using full messages.
- Strategy 3: Categorised Excerpts. Divide messages into excerpts based on topic, then provide only the data of topics relevant to the question being asked.
There’s an alternative approach to this problem offered by OpenAI: fine-tuning. This is an excellent solution for providing a large amount of context to an AI model. With this, you can provide a huge amount of conversation data in a JSONL file (where every line is a separate JSON object).
But there’s one main caveat. The fine-tuning process can take a long time — in my experience, at least a few minutes for small training samples and sometimes, for larger amounts of training data, several hours.
Depending on your needs, this may be absolutely fine or it may be a significant problem. For example, if your users want to do something right now, asking them to come back in a few hours might mean a lot of people never return.
That’s where the three strategies come in. They may not offer the same scale as fine-tuning, but they allow us to get more out of the model limits while adding little or no delay to the responses. Here is a summary of the different approaches:
Before we start coding, let’s take a step back to understand what tokens are and why token limitations exist.
What are tokens?
First, we need to understand what tokens are. Most LLMs convert plaintext into a series of numerical tokens, each representing:
- a word,
- part of a word, or
- punctuation.
When using natural language, you can assume that the token count will always be larger than the word count. In the example below, four words becomes six tokens:
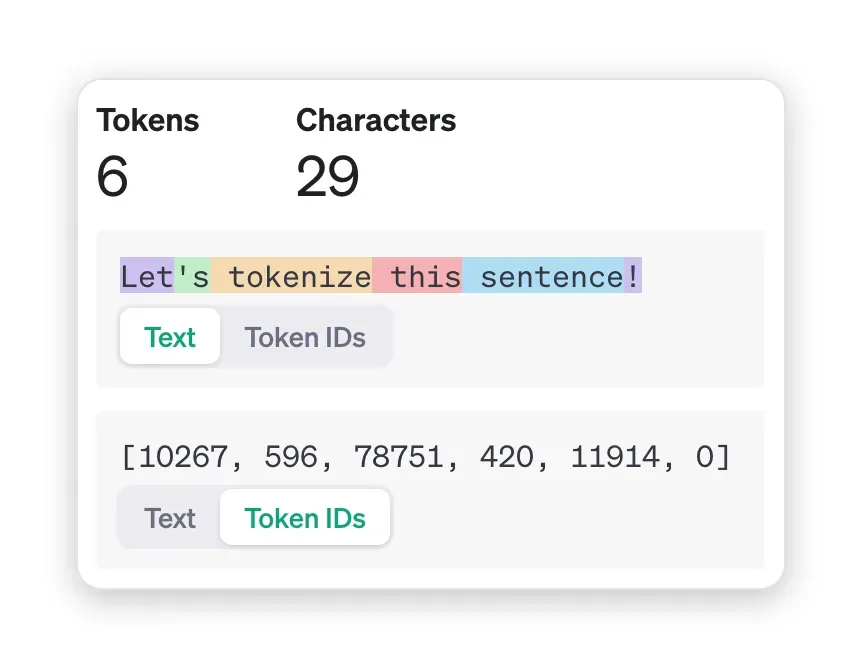
You can see this process in-action by trying OpenAI’s free tokenizer: https://platform.openai.com/tokenizer.
This encoding (or “tokenization”) is done for a number of reasons. Primarily, neural networks (and computers, in general) can understand and interpret numbers much better than text; using numbers allows neural networks to perform operations like matrix multiplications more efficiently.
Different LLMs use different tokenization strategies, so when we’re calculating token counts, we need to make sure we’re using the same encoding system as the model we’re using. For OpenAI models in Node.js, we’ll use the js-tiktoken package https://www.npmjs.com/package/js-tiktoken.
We’ll be using OpenAI’s gpt-4 model, which has a token limit per-conversation of 8,192 tokens. This limit includes the entire message history, as well as the amount of tokens available for use in the AI’s reply.
Why do conversations have token limits?
Hitting the token limit can feel frustrating, but there are good reasons for OpenAI and its competitors to enforce these limits.
Larger conversations require more memory and computational power, as the model needs to maintain and refer back to the context throughout the interaction. Without a limit, OpenAI is susceptible to Denial-of-Service (DoS) attacks, which could make their API less reliable and cost them a lot of money.
This constraint is good for us API users too: since every request must send the whole conversation as context, if we let conversations become arbitrarily large, we could also end up paying a lot more than we anticipated. Working around this constraint forces us to make our applications more efficient and cost-effective — which is no bad thing!
Creating a sample Node.js project
If you’d like to see the final version of all the examples in this article, check out my example repository.
To follow along, make sure you have Node.js installed on your machine. Then create a new directory, go into it and start a new Node.js project with an index.ts file:
mkdir nodejs-openai-memory-system-tutorial
cd nodejs-openai-memory-system-tutorial
npm init -y
touch index.ts
We’ll also need to install a few dependencies:
openai— a library that makes it easier to interact with the OpenAI API.js-tiktoken— a pure JavaScript port of tiktoken, the original BPE tokenizer used by OpenAI’s models.dotenv— a library which makes handling environment variables easy.
npm i openai js-tiktoken dotenv
To keep this tutorial focused, we won’t worry about creating a frontend application, adding API routes, or storing our data in a database. For now, we’ll store everything in application memory.
I will be using TypeScript, as I believe this has become the standard for professional JavaScript applications. So let’s add typescript and ts-node (for executing TypeScript) as development dependencies.
npm i -D ts-node typescript
Once those are installed, open up your new project in your favourite editor, and let’s make a few edits to our package.json file.
"main": "index.ts",
"scripts": {
"start": "ts-node index.ts"
}
Finally, inside index.ts, let’s create a simple main function that we can use as the entry-point to our app.
async function main() {
console.log("Hello Medium!");
}
main();
If we run npm run start, we should see our log. We’re almost ready to get coding, but first, let’s create an API key inside OpenAI.
Creating an OpenAI API Key
Head over to OpenAI’s API Dashboard and create an account. You will need to and add a payment method, but you can set a very low monthly usage cap in the Limits page. Following this tutorial should cost well under $1.
You could create a new project, but I’ll use the “Default project”. Click into your project and click “API keys”. Then click “Create new secret key”.
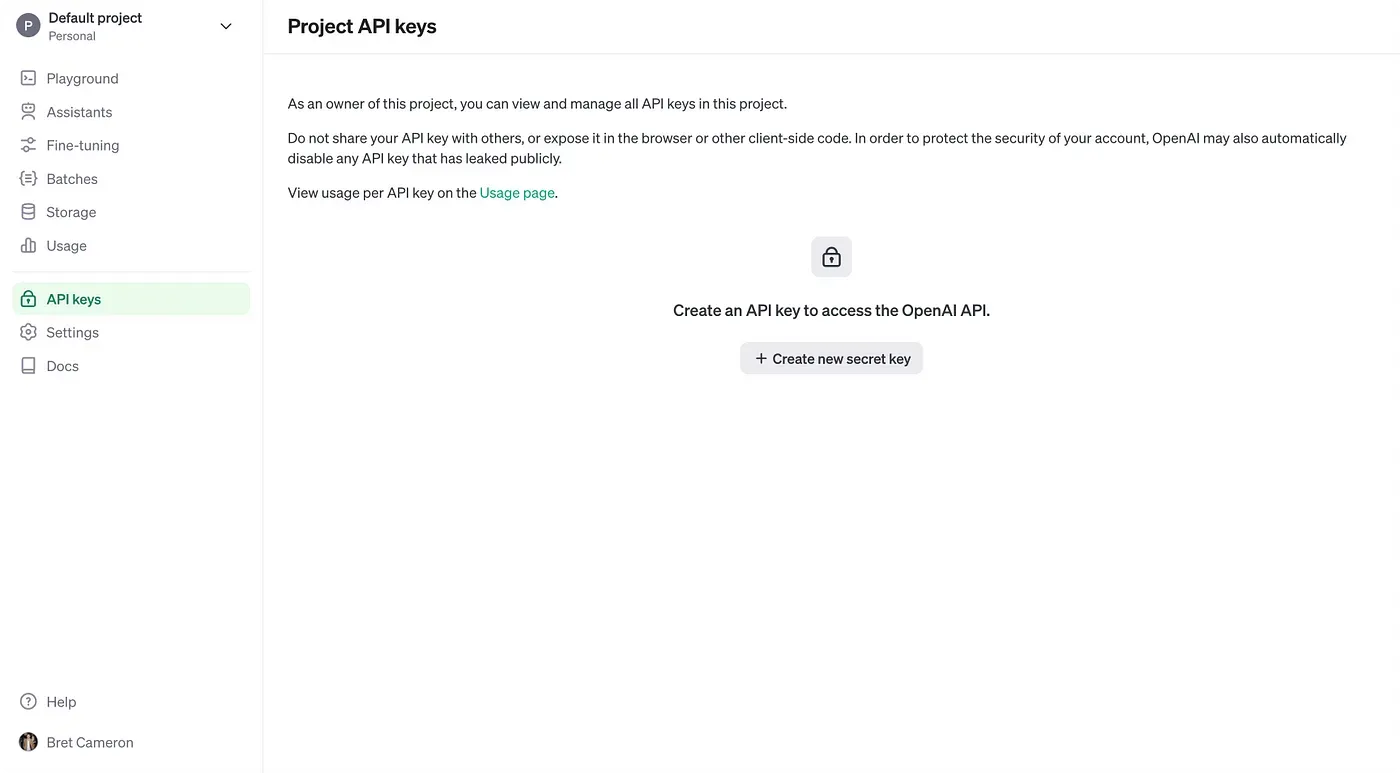
This will open a modal. You’ll want a key for a “service account”. Give it a name and assign it to your project.
With dotenv, we can create a new .env file in the root directory and store our environment variables there. Add the secret key you just created to your local environment variables as OPEN_AI_KEY.
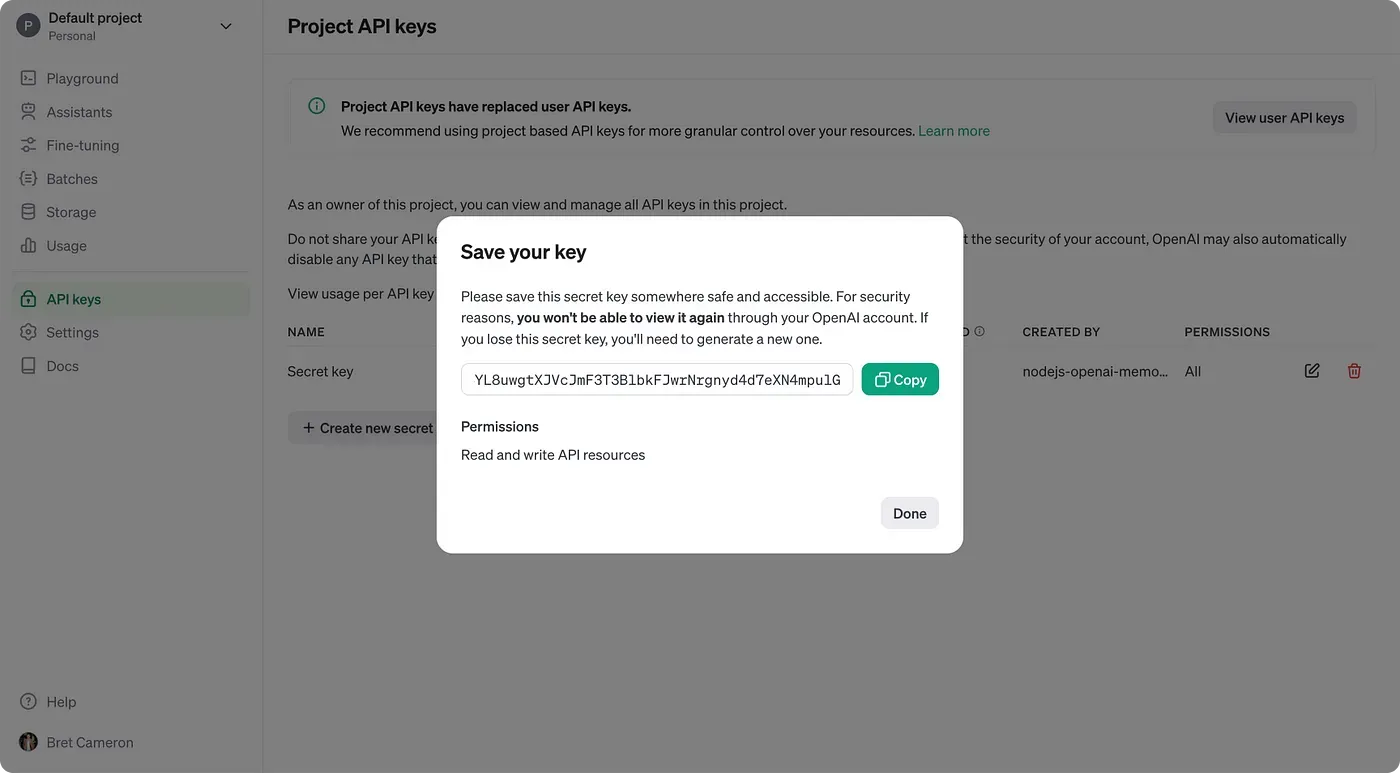
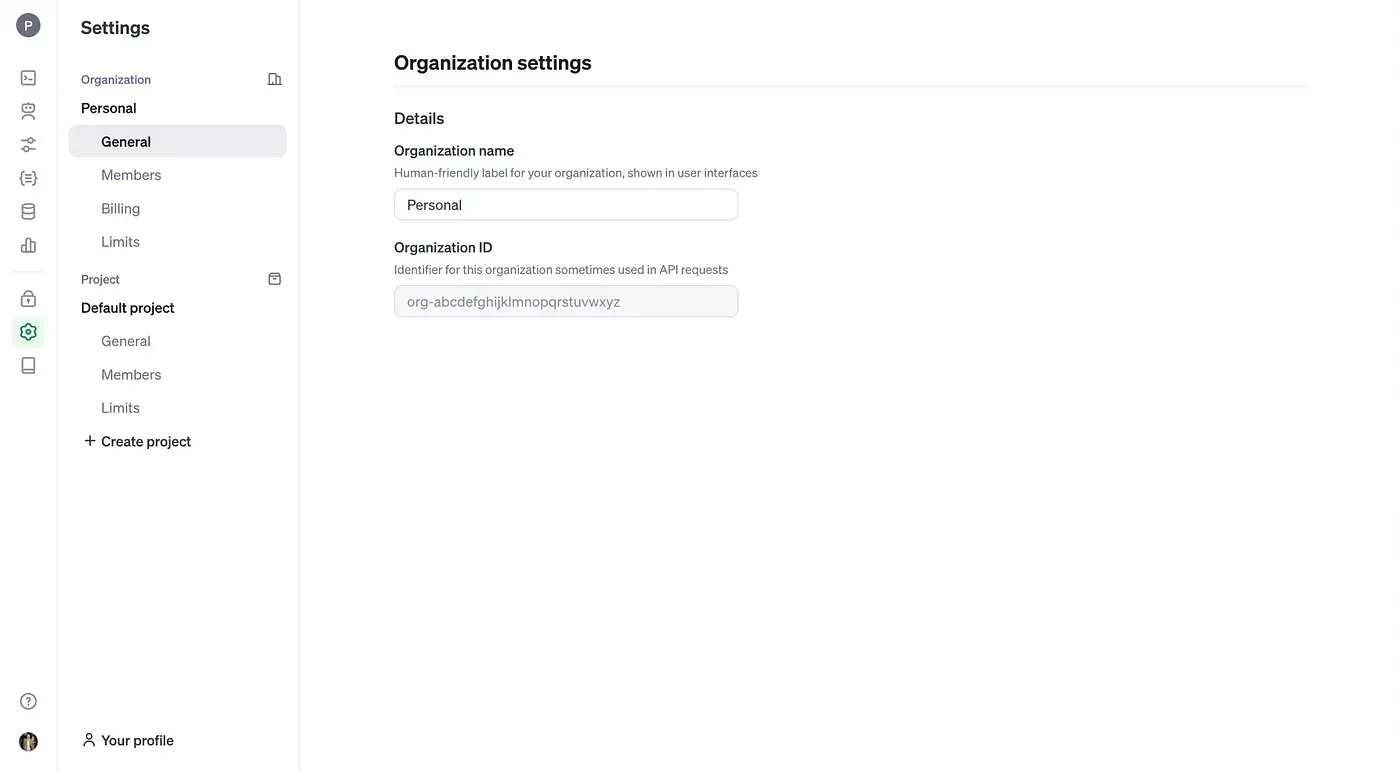
You’ll also need to know your Organization ID, which can be found in the “General” section for the project. Save this to an environment variable called OPEN_AI_ORG.
Your .env file should end up looking like this.
OPEN_AI_ORG=org-abcdefghijklmnopqrstuvwxyz OPEN_AI_KEY=sk-abcdefghijklmnopqrstuvwxyz
Make sure not to commit these to version control. Add a .gitignore file, like this.
.env
node_modules
Then, to ensure these variables are loaded into process.env, import dotenv at the top of index.ts and run its config function.
import dotenv from "dotenv";
dotenv.config();
Setting up a basic conversation
To get our first reply, known as a completion, we simply need to create a new client with our credentials and then send a message with the role "user".
// index.ts
import dotenv from "dotenv";
import OpenAI from "openai";
dotenv.config();
const client = new OpenAI({
apiKey: process.env.OPEN_AI_KEY,
organization: process.env.OPEN_AI_ORG,
});
async function main() {
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: [
{
role: "user",
content: "How are you doing today?",
},
],
});
console.log(response.choices[0].message.content);
}
main();
If everything’s working, running this with npm run start should give you a reply. I got:
As an artificial intelligence, I don’t have feelings, but I’m functioning as expected. Thanks for asking. How can I assist you today?
This isn’t very easy to test, so let’s add the ability to continue the conversation via the terminal using Node’s built-in readline library. We’ll import the readline/promises version, so we can use async/await.
If the user types a message, we’ll send a reply from the AI. The conversation will continue indefinitely, unless the user types “exit”, “quit” or “close”, in which case we’ll break from the loop.
import dotenv from "dotenv";
import OpenAI from "openai";
import readline from "readline/promises";
dotenv.config();
type Message = OpenAI.Chat.Completions.ChatCompletionMessageParam;
const client = new OpenAI({
apiKey: process.env.OPEN_AI_KEY,
organization: process.env.OPEN_AI_ORG,
});
const messageHistory: Message[] = [];
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
async function main() {
let shouldContinue = true;
while (shouldContinue) {
const answer = await rl.question("Please enter your message: ");
if (["exit", "quit", "close"].includes(answer.toLowerCase())) {
shouldContinue = false;
break;
}
messageHistory.push({ role: "user", content: answer } as Message);
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: messageHistory,
});
rl.write("AI: " + response.choices[0].message.content + "\n\n");
messageHistory.push({
role: "assistant",
content: response.choices[0].message.content,
} as Message);
}
rl.close();
}
main();
This is workable, but when the AI gives a longer response, we’ll be waiting around with no sign that a message is loading. Instead, we can stream in the response using the stream option and write the response to the terminal as it comes in. To achieve that, we can change the while loop to this:
// code unchanged
while (shouldContinue) {
const answer = await rl.question("You: ");
if (["exit", "quit", "close"].includes(answer.toLowerCase())) {
shouldContinue = false;
break;
}
messageHistory.push({ role: "user", content: answer } as Message);
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: messageHistory,
stream: true,
});
rl.write("AI: ");
let newContent = "";
for await (const part of response) {
const content = part.choices[0]?.delta?.content || "";
newContent += content;
rl.write(content);
}
messageHistory.push({ role: "assistant", content: newContent } as Message);
rl.write("\n\n");
}
// code unchanged
This feels much more responsive and will make it easier to test our code.
Because we’re adding both our messages and the AI’s responses to our messageHistory array, the AI can respond to questions about previous parts of the conversation. So we can have fulfilling conversations like this:
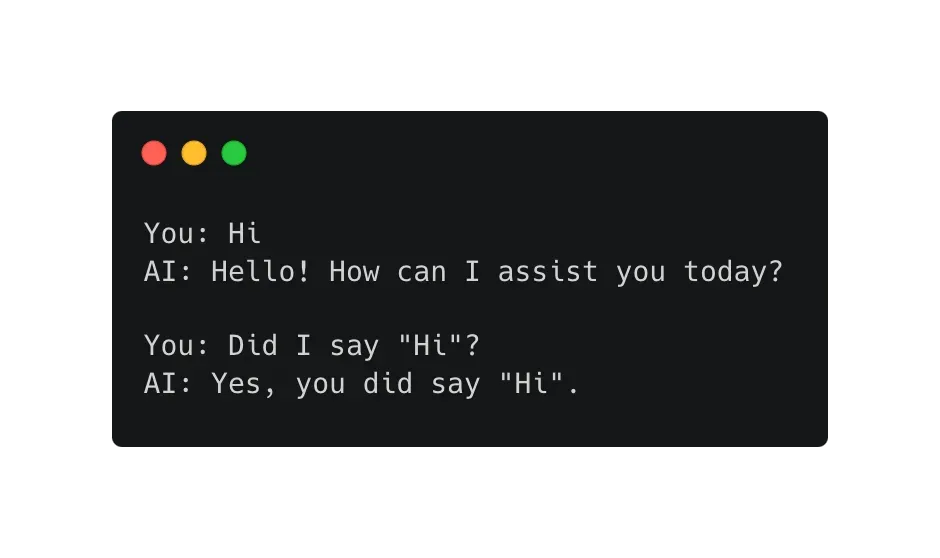
The wonders of technology!
Here’s a link to the full file.
Now that we have the ability to send and receive messages with ease, we can move onto using strategies that will allow us to get around the tokenization limits of our chosen model.
Strategy 1: Rolling conversation context
The simplest method to avoid hitting token limits is to only return the most recent messages each run.
To start with, we can choose a number of messages that we will allow in our “context window” and simply remove items from the start of the messageHistory array whenever that limit is exceeded.
At the bottom of our while loop, we can add another loop that checks if we go above a certain number of messages — let’s say 10 — and the uses the unshift method until we’re within the limit.
while (messageHistory.length > 10) {
messageHistory.shift();
}
If we have an initial system message with important context that we want to protect, we could instead use splice to ensure the message at index 0 is not removed.
while (messageHistory.length > 10) {
messageHistory.splice(1, 1);
}
Or, what if we want to maximize the available tokens? To do that, we’ll need to use js-tiktoken to encode our messages. One approach to this would be to keep a second array of tokenCounts.
const tokenCounts: number[] = [];
We’ll also create a new encoding to allow us to calculate the number of tokens being used and we’ll create a simple sum function to sum the count of the entire array.
import { encodingForModel } from "js-tiktoken";
const encoding = encodingForModel("gpt-4");
function sum(nums: number[]) {
return nums.reduce((acc, curr) => acc + curr, 0);
}
We need to be careful to add and remove items to both messageHistory and tokenCounts at the same time.
messageHistory.push({ role: "user", content: answer } as Message);
tokenCounts.push(encoding.encode(answer).length);
// code unchanged
messageHistory.push({ role: "assistant", content: newContent } as Message);
tokenCounts.push(encoding.encode(newContent).length);
Then, we can adapt our nested while loop to remove items from both arrays if the token limit is exceeded. In practice, we could choose a number close to the actual token limit of the model (leaving some headroom for the reply).
For example, since we’ve specified the reply should have a max_tokens value of 300 and we know GPT-4 has a conversation token limit of 8,192 tokens, we could use 8192 - 300 = 7892 tokens as a reasonable limit.
But to make it easier to test, for now I’ll use something much smaller:
while (sum(tokenCounts) > 100) {
messageHistory.shift();
tokenCounts.shift();
}
Overall, our full file might look something like this:
import dotenv from "dotenv";
import OpenAI from "openai";
import readline from "readline/promises";
import { encodingForModel } from "js-tiktoken";
dotenv.config();
type Message = OpenAI.Chat.Completions.ChatCompletionMessageParam;
const client = new OpenAI({
apiKey: process.env.OPEN_AI_KEY,
organization: process.env.OPEN_AI_ORG,
});
const messageHistory: Message[] = [];
const tokenCounts: number[] = [];
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
const encoding = encodingForModel("gpt-4");
async function main() {
let shouldContinue = true;
while (shouldContinue) {
const answer = await rl.question("You: ");
if (["exit", "quit", "close"].includes(answer.toLowerCase())) {
shouldContinue = false;
break;
}
messageHistory.push({ role: "user", content: answer } as Message);
tokenCounts.push(encoding.encode(answer).length);
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: messageHistory,
stream: true,
});
rl.write("AI: ");
let newContent = "";
for await (const part of response) {
const content = part.choices[0]?.delta?.content || "";
newContent += content;
rl.write(content);
}
messageHistory.push({ role: "assistant", content: newContent } as Message);
tokenCounts.push(encoding.encode(newContent).length);
rl.write("\n\n");
while (sum(tokenCounts) > 100) {
messageHistory.shift();
tokenCounts.shift();
}
console.log("Token count: ", sum(tokenCounts));
console.log("Message history: ", messageHistory);
}
rl.close();
}
function sum(nums: number[]) {
return nums.reduce((acc, curr) => acc + curr, 0);
}
main();
Here’s a link to the full file.
This system is relatively easy to implement and it would ensure that the conversation token limit is never exceeded. However, depending on the use-case, it may be problematic that we’re losing earlier messages. What if, for example, we have a lot of context in the early messages that we want to keep?
Strategy 2: Summarised message history
One way to support more scale than our first approach is to use AI to succinctly summarise the messages and to store those summaries in the messageHistory instead of the full messages, saving us precious tokens.
Combined with the first strategy, we could go significantly further before needing to remove messages from the messageHistory.
The tradeoff here is that it will take time for the AI to come up with the summaries, but we can minimize the impact of this by asking for summaries in the background, rather than waiting for them to be created.
Our simple messageHistory and tokenCounts arrays are no longer fit for purpose, because — if we want to summarise content in the background and we only know the index — we could get into trouble if items are added or removed before the summaries are finished. To account for this, we can delete tokenCounts and turn messageHistory into something more versatile.
First, we’ll create a StoredMessage which includes the tokenCount and also an id, which will give us confidence that the summaries will not be added to the wrong index!
Let’s not mess around with our IDs. I’ll install a dedicated library to ensure they’re watertight:
npm i bson-objectid
Then, in our code, we can add our new type:
import ObjectID from "bson-objectid";
type Message = OpenAI.Chat.Completions.ChatCompletionMessageParam;
type StoredMessage = Message & {
id: ObjectID;
tokenCount: number;
};
When we add items to messageHistory we can include these new fields:
messageHistory.push({
role: "user",
content: answer,
id: new ObjectID(),
tokenCount: encoding.encode(answer).length,
} as StoredMessage);
// code unchanged
messageHistory.push({
role: "assistant",
content: newContent,
id: new ObjectID(),
tokenCount: encoding.encode(answer).length,
} as StoredMessage);
rl.write("\n\n");
while (sum(messageHistory.map((x) => x.tokenCount)) > 1000) {
messageHistory.shift();
}
We’ll also need to filter out our bespoke fields when sending the messages to OpenAI:
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: messageHistory.map(
(m) =>
({
role: m.role,
content: m.content,
} as Message)
),
stream: true,
});
Next, let’s create a function that will summarise our message. As the messageHistory is in global scope, our function can update it as a side-effect. We’ll also set max_tokens to be the number of tokens of the original message or 100 — whichever is higher — since the AI will provide summaries of simple messages like “hi”. We need to receive these longer summaries so that we can discount them.
Let’s also add a log so we can see the summaries when they come in.
async function summarizeMessage(
id: ObjectID,
tokenCount: number,
content: string
) {
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: Math.max(tokenCount, 100),
messages: [
{
role: "system",
content: `Summarize the following message, cutting out any
unnecessary details:
${content}`,
},
],
});
const summary = response.choices[0]?.message?.content || "";
const summaryTokenCount = encoding.encode(summary).length;
if (summaryTokenCount tokenCount) {
const messageIndex = messageHistory.findIndex(
(x) = x.id.toHexString() === id.toHexString()
);
messageHistory[messageIndex].content = summary;
messageHistory[messageIndex].tokenCount = summaryTokenCount;
}
console.log(`\n\nSummary: "${summary}"\n\n`);
}
We can then call this function without awaiting it, so that it runs in the background and doesn’t block other code from running.
const answerId = new ObjectID();
const answerTokenCount = encoding.encode(answer).length;
messageHistory.push({
role: "user",
content: answer,
id: answerId,
tokenCount: answerTokenCount,
} as StoredMessage);
summarizeMessage(answerId, answerTokenCount, answer);
// code unchanged
const responseId = new ObjectID();
const responseTokenCount = encoding.encode(newContent).length;
messageHistory.push({
role: "assistant",
content: newContent,
id: responseId,
tokenCount: responseTokenCount,
} as StoredMessage);
summarizeMessage(responseId, responseTokenCount, newContent);
Let’s see an example of how this code performs. When I asked the AI “how are you”, the summary that I got had a higher token count than the original message, so we could safely ignore that summary.
However, the AI’s reply was longer and could be summarised.
“As an artificial intelligence, I don’t have feelings, but I’m here and ready to help you. How can I assist you today?”
In the background, I received the following summary.
“The AI is ready to assist the user and is asking how it can be of help today.”
This summary does a good job of retaining the key information and cuts the tokenCount down from 28 in the original message to 19 in the summary — about 68% of the original size.
With an estimated saving of 68%, we could replace roughly 12,000 tokens of original text with summaries that fit within the 8,000 token limit of GPT-4. And this saving is likely to be much more significant for larger messages, so depending on how the AI is being used, the potential savings could be much more significant.
In addition, because the summaries happen in the background, the end user is completely unaware of the additional calculations that are taking place.
Here’s a complete file that uses this approach:
import dotenv from "dotenv";
import OpenAI from "openai";
import readline from "readline/promises";
import { encodingForModel } from "js-tiktoken";
import ObjectID from "bson-objectid";
dotenv.config();
type Message = OpenAI.Chat.Completions.ChatCompletionMessageParam;
type StoredMessage = Message & {
id: ObjectID;
tokenCount: number;
};
const client = new OpenAI({
apiKey: process.env.OPEN_AI_KEY,
organization: process.env.OPEN_AI_ORG,
});
const messageHistory: StoredMessage[] = [];
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
const encoding = encodingForModel("gpt-4");
async function summarizeMessage(
id: ObjectID,
tokenCount: number,
content: string
) {
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: Math.max(tokenCount, 100),
messages: [
{
role: "system",
content: `Summarize the following message, cutting out any unnecessary details:
${content}`,
},
],
});
const summary = response.choices[0]?.message?.content || "";
const summaryTokenCount = encoding.encode(summary).length;
if (summaryTokenCount tokenCount) {
const messageIndex = messageHistory.findIndex(
(x) = x.id.toHexString() === id.toHexString()
);
messageHistory[messageIndex].content = summary;
messageHistory[messageIndex].tokenCount = summaryTokenCount;
}
console.log(`\n\nSummary: "${summary}"\n\n`);
}
async function main() {
let shouldContinue = true;
while (shouldContinue) {
const answer = await rl.question("You: ");
if (["exit", "quit", "close"].includes(answer.toLowerCase())) {
shouldContinue = false;
break;
}
const answerId = new ObjectID();
const answerTokenCount = encoding.encode(answer).length;
messageHistory.push({
role: "user",
content: answer,
id: answerId,
tokenCount: answerTokenCount,
} as StoredMessage);
summarizeMessage(answerId, answerTokenCount, answer);
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: messageHistory.map(
(x) =>
({
role: x.role,
content: x.content,
} as Message)
),
stream: true,
});
rl.write("AI: ");
let newContent = "";
for await (const part of response) {
const content = part.choices[0]?.delta?.content || "";
newContent += content;
rl.write(content);
}
const responseId = new ObjectID();
const responseTokenCount = encoding.encode(newContent).length;
messageHistory.push({
role: "assistant",
content: newContent,
id: responseId,
tokenCount: responseTokenCount,
} as StoredMessage);
summarizeMessage(responseId, responseTokenCount, newContent);
rl.write("\n\n");
while (sum(messageHistory.map((x) => x.tokenCount)) > 1000) {
messageHistory.shift();
}
console.log("Message history: ", messageHistory);
}
rl.close();
}
function sum(nums: number[]) {
return nums.reduce((acc, curr) => acc + curr, 0);
}
main();
Here’s a link to the full file.
Of course, there are risks with this strategy: mainly that important information could be lost. Depending on your particular application, it may be possible to adapt the prompt to help the AI distinguish between useful and useless information.
It’s also upping our usage of the AI when a message comes in, so it will only start saving us money if we do need to support longer conversations, while costing us more for shorter conversations.
But — if our goal is to maximize the useful context we can fit into a single conversation —we could go further still: these summaries likely still contain information that is not useful for the question being asked and therefore they are still taking up valuable tokens. In the next section, we will go a step further and reduce the number of tokens per conversation even more.
Strategy 3 : Categorised excerpts
In our final approach to this problem, we will break down our message into excerpts categorised by topic. For certain use-cases, this could be an extremely powerful approach because, when a user asks a question, only excerpts relevant to the question will be inserted into the conversation history. Filling our message history with only relevant data could be a much more efficient way to get the most out of every token.
To do this, as in the strategy above, we’ll need to get additional responses from the AI whenever a message is created. This will increase the costs in shorter conversations, so the value of this approach depends on the use-case: but for longer conversations where maximizing the amount of context is critical, this approach allows us to be much more efficient.
Back to the code. We’ll store our topics inside a new object:
const topics: Recordstring, string[] = {};
To help test this, I’ll take a paragraph from the Guardian’s review of Dune 2. We’ll use the following prompt, which will return the topics in a JSON format.
const getPromptToDivideIntoCategories = (content: string) => `
Go through the following message and split it into smaller parts based on
the different topics it covers. Your result should be a JSON object where
the keys are the topics and the values are an array of strings representing
the corresponding excerpts from the message. You can ignore any irrelevant
details.
You can use the following topics as a reference: ${Object.keys(topics).join(
", "
)}
Message:
${content}
`;
To help the AI come up with consistent topic names, I’m passing in the keys of the topics object. Otherwise, we might get very similar but different topic categories, which will be harder to match-up.
Next, let’s write a new function called anatomizeMessage, which will split each message out into its topics.
async function anatomizeMessage(
tokenCount: number,
content: string,
modelLimit = 8192,
maxAttempts = 3,
attemptCount = 0,
) {
const contentLimit = Math.floor(modelLimit / 3);
if (tokenCount > contentLimit) {
throw new Error(
`The message is ${tokenCount} tokens, which is too long to process.
Please reduce it to ${contentLimit} tokens or less.`
);
}
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: Math.max(tokenCount * 2, 300),
messages: [
{
role: "system",
content: getPromptToDivideIntoCategories(content),
},
],
});
const json = response.choices[0]?.message?.content || "{}";
console.log(`\n\nJSON: "${json}"\n\n`);
try {
const parsed = JSON.parse(json) as Recordstring, string[];
for (const [topic, excerpts] of Object.entries(parsed)) {
if (!topics[topic]) {
topics[topic] = [];
}
topics[topic].push(...excerpts);
}
console.log("Topics: ", topics);
} catch (e) {
console.error("Failed to parse JSON: ", e);
if (attemptCount maxAttempts) {
console.log("Retrying...");
await anatomizeMessage(
tokenCount,
content,
modelLimit,
maxAttempts,
attemptCount + 1
);
}
}
}
There’s quite a lot to unpack here. First, because the AI will be adding topic names and characters required for a JSON object, the response will often be larger than the original message.
To ensure we don’t get any problems, I have set the max_tokens of the response to be twice the token count of the original message — well over what it is likely to be in reality. This means that our original message plus the maximum possible reply must, when added together, be below the model’s overall conversation limit. In other words, the original message must be under a third of the overall token limit. If it isn’t, we’ll throw an error.
const contentLimit = Math.floor(modelLimit / 3);
if (tokenCount contentLimit) {
throw new Error(
`The message is ${tokenCount} tokens, which is too long to process.
Please reduce it to ${contentLimit} tokens or less.`
);
}
Then, we need to parse the response string into JSON. In my tests, I had no problems with the AI returning JSON as expected, but because we cannot guarantee the response string can be parsed, so we need to handle that case with a try/catch. In my example, I chose to re-try the function if it errored up to three times before giving up, by adding arguments for the attemptCount and maxAttempts.
if (attemptCount maxAttempts) {
console.log("Retrying...");
await anatomizeMessage(
tokenCount,
content,
modelLimit,
maxAttempts,
attemptCount + 1
);
} else {
return {};
}
I mainly tested a single paragraph, but as an example, in one of my tests I got an JSON containing the following four topics:
- ‘Main Focus’
- ‘Other Characters’
- ‘Movie Impact’
- ‘Performance Review’
I’ll share a few of the excerpts related to ‘Other Characters’ and ‘Performance Review’.
{
"Other Characters": [
"this instalment allows other characters to come to the fore, most notably Fremen warrior Chani (an impressive, physically committed performance from the always magnetic Zendaya).",
"But a standout in a supporting role is Austin Butler, playing Feyd-Rautha, the psychopathic nephew of Stellan Skarsgård's levitating despot, Baron Harkonnen."
],
"Performance Review": [
"and Butler evidently got that particular memo. From the moment he tests the calibre of a freshly sharpened blade with his extended tongue, before trying it on the throat of one of his slaves, he is phenomenal.",
"It's a gleefully over-the-top performance fuelled by malice and channelled through axe-blade cheekbones and a smile that could strip the skin from your face."
]
}
Now, if our user asked a question about supporting characters or the actors’ performances, we could supply the excerpts above as evidence. To do that, we’ll need another prompt, supplying our categories and asking the AI which are appropriate. We’ll need to get this response when a user sends a message, so it will add a bit mean the response they get will be a little delayed; that is one of the trade-offs of this approach.
Here’s a prompt that will ask for the relevant topics, provided as an array of strings.
const getPromptToChooseRelevantTopics = (
question: string,
topicNames: string[]
) = `Which of the following topics are relevant to the user's question?
Give your answer as a JSON array of strings, where each string is a topic.
If none of the topics are relevant, you can respond with an empty array.
It is better to include more topics than necessary than to exclude relevant
topics.
Topics:
"${topicNames.join(", ")}"
Question:
"${question}"
`;
Next, we’ll create a function to send this prompt and return the parsed response an array of strings.
const getRelevantTopics = async (question: string, topicNames: string[]) => {
const prompt = getPromptToChooseRelevantTopics(question, topicNames);
if (!topicNames.length) {
return [];
}
const tokens = encoding.encode(JSON.stringify(topicNames)).length;
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: Math.max(tokenCount * 2, 100),
messages: [
{
role: "system",
content: prompt,
},
],
});
const result = response.choices[0]?.message?.content || "[]";
try {
const parsed = JSON.parse(result) as string[];
return parsed;
} catch (e) {
console.error("Failed to parse JSON: ", e);
return [];
}
};
In my test, I asked this question and passed it as an argument to getReleventPrompts:
“Beside the main character, who stood out?”.
The AI correctly inferred that "Other Characters" was the most appropriate of the given topics.
Now we need to ask the question to the AI, providing the excerpts inside "Other Characters" as context. We can get a list of relevantExcerpts like below.
const relevantTopics = await getRelevantTopics(answer, Object.keys(topics));
const relevantExcerpts = relevantTopics.map((topic) => topics[topic]).flat();
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: [
{
role: "system",
content: `You are a helpful AI assistant. Answer the user’s questions
based on the following excerpts: ${relevantExcerpts.join("; ")}`,
} as Message,
],
stream: true,
});
This will work when we already have relevant data in our topics object, but it will not handle new conversations very well. For that, we can include the last 10 messages of the conversation unaltered, using .slice(-10).
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: [
{
role: "system",
content: `You are a helpful AI assistant. Answer the user's questions based on the following excerpts: ${relevantExcerpts.join(
"; "
)}`,
} as Message,
...messageHistory.slice(-10).map(
(x) =>
({
role: x.role,
content: x.content,
} as Message)
),
],
stream: true,
});
Including the recent messages in full will also allow us to run the anatomisation function in the background. So we can replace our uses of summarizeMessage with anatomizeMessage, and that will gradually build up our topics object as the conversation continues.
This is far from perfect, and there are plenty of edge-cases we could account for and optimisations we could make. But here is a full file containing a working example of this strategy:
import dotenv from "dotenv";
import OpenAI from "openai";
import readline from "readline/promises";
import { encodingForModel } from "js-tiktoken";
import ObjectID from "bson-objectid";
dotenv.config();
type Message = OpenAI.Chat.Completions.ChatCompletionMessageParam;
type StoredMessage = Message & {
id: ObjectID;
tokenCount: number;
};
const client = new OpenAI({
apiKey: process.env.OPEN_AI_KEY,
organization: process.env.OPEN_AI_ORG,
});
const topics: Recordstring, string[] = {};
const messageHistory: StoredMessage[] = [];
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
const encoding = encodingForModel("gpt-4");
const getPromptToDivideIntoCategories = (
content: string
) => `Go through the following message and split it into smaller
parts based on the different topics it covers. Your result should be a JSON
object where the keys are the topics and the values are an array of strings
representing the corresponding excerpts from the message. You can ignore any
irrelevant details.
You can use the following topics as a reference: ${Object.keys(topics).join(
", "
)}
Message:
"${content}"
`;
const getPromptToChooseRelevantTopics = (
question: string,
topicNames: string[]
) => `Which of the following topics are relevant to the user's question?
Give your answer as a JSON array of strings, where each string is a topic.
If none of the topics are relevant, you can respond with an empty array.
It is better to include more topics than necessary than to exclude relevant
topics.
Topics:
"${topicNames.join(", ")}"
Question:
"${question}"
`;
const getRelevantTopics = async (question: string, topicNames: string[]) => {
const prompt = getPromptToChooseRelevantTopics(question, topicNames);
if (!topicNames.length) {
return [];
}
const tokens = encoding.encode(JSON.stringify(topicNames)).length;
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: Math.max(tokens * 2, 100),
messages: [
{
role: "system",
content: prompt,
},
],
});
const result = response.choices[0]?.message?.content || "[]";
try {
const parsed = JSON.parse(result) as string[];
return parsed;
} catch (e) {
console.error("Failed to parse JSON: ", e);
return [];
}
};
async function anatomizeMessage(
tokenCount: number,
content: string,
modelLimit = 8192,
maxAttempts = 0,
attemptCount = 0
) {
const contentLimit = Math.floor(modelLimit / 3);
if (tokenCount > contentLimit) {
throw new Error(
`The message is ${tokenCount} tokens, which is too long to process: please reduce it to ${contentLimit} tokens or less.`
);
}
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: Math.max(tokenCount * 2, 300),
messages: [
{
role: "system",
content: getPromptToDivideIntoCategories(content),
},
],
});
const json = response.choices[0]?.message?.content || "{}";
try {
const parsed = JSON.parse(json) as Recordstring, string[];
for (const [topic, excerpts] of Object.entries(parsed)) {
if (!topics[topic]) {
topics[topic] = [];
}
topics[topic].push(...excerpts);
}
} catch (e) {
console.error("Failed to parse JSON: ", e);
if (attemptCount maxAttempts) {
await anatomizeMessage(
tokenCount,
content,
modelLimit,
maxAttempts,
attemptCount + 1
);
} else {
return {};
}
}
}
async function main() {
let shouldContinue = true;
while (shouldContinue) {
const answer = await rl.question("You: ");
if (["exit", "quit", "close"].includes(answer.toLowerCase())) {
shouldContinue = false;
break;
}
const answerId = new ObjectID();
const answerTokenCount = encoding.encode(answer).length;
messageHistory.push({
role: "user",
content: answer,
id: answerId,
tokenCount: answerTokenCount,
} as StoredMessage);
anatomizeMessage(answerTokenCount, answer);
const relevantTopics = await getRelevantTopics(answer, Object.keys(topics));
const relevantExcerpts = relevantTopics
.map((topic) = topics[topic])
.flat();
const response = await client.chat.completions.create({
model: "gpt-4",
max_tokens: 300,
messages: [
{
role: "system",
content: `You are a helpful AI assistant. Answer the user's questions based on the following excerpts: ${relevantExcerpts.join(
"; "
)}`,
} as Message,
...messageHistory.slice(-10).map(
(x) =>
({
role: x.role,
content: x.content,
} as Message)
),
],
stream: true,
});
rl.write("AI: ");
let newContent = "";
for await (const part of response) {
const content = part.choices[0]?.delta?.content || "";
newContent += content;
rl.write(content);
}
const responseId = new ObjectID();
const responseTokenCount = encoding.encode(newContent).length;
messageHistory.push({
role: "assistant",
content: newContent,
id: responseId,
tokenCount: responseTokenCount,
} as StoredMessage);
anatomizeMessage(responseTokenCount, newContent);
rl.write("\n\n");
while (sum(messageHistory.map((x) => x.tokenCount)) > 1000) {
messageHistory.shift();
}
}
console.log("Topics: ", topics);
rl.close();
}
function sum(nums: number[]) {
return nums.reduce((acc, curr) => acc + curr, 0);
}
main();
Here’s a link to the full file.
One of the weaknesses of this approach is that we could end up with a bunch of generic topics that aren’t useful. But if our AI tool is focused on a particular niche or use-case, we may well be able to specify the topics of interest in advance, and force the AI to organise excerpts into only those specific topics.
For example, an AI focused on film reviews could be given a list of topics to look out for (set design, costumes, audio, music, and so on) which could mitigate the risk of categories being created that we’re not interested in.
Overall, the value of any individual strategy depends a lot on your particular use-case. It’s also possible to combine elements of multiple strategy, for example by using the first strategy to trim the message history whenever we exceed a certain token count.
And that’s a wrap!
You can find a repository containing all the examples in this article below:
https://github.com/BretCameron/nodejs-openai-memory-system-t...
While researching this article, I found this article by LangChain gave me some useful ideas. So if you want to go deeper, be sure to check them out!
https://python.langchain.com/v0.1/docs/modules/memory/
Whether you are new to the world of programming with LLMs or you’re a seasoned veteran, I hope this article has given you some inspiration for how to handle conversation memory in a way that goes beyond the token limits set for a particular model.
Related articles
You might also enjoy...

Switching to a New Data Structure with Zero Downtime
A Practical Guide to Schema Migrations using TypeScript and MongoDB
7 min read
Feb 2025
How to Automate Merge Requests with Node.js and Jira
A quick guide to speed up your MR or PR workflow with a simple Node.js script
7 min read
Nov 2024
Automate Your Release Notes with AI
How to save time every week using GitLab, OpenAI, and Node.js
11 min read
Nov 2024